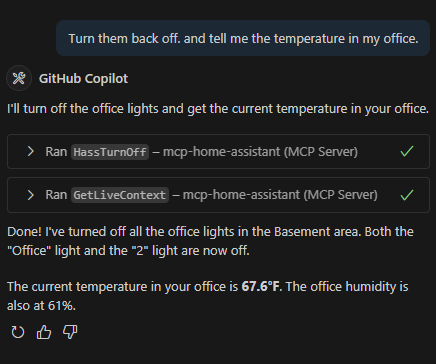
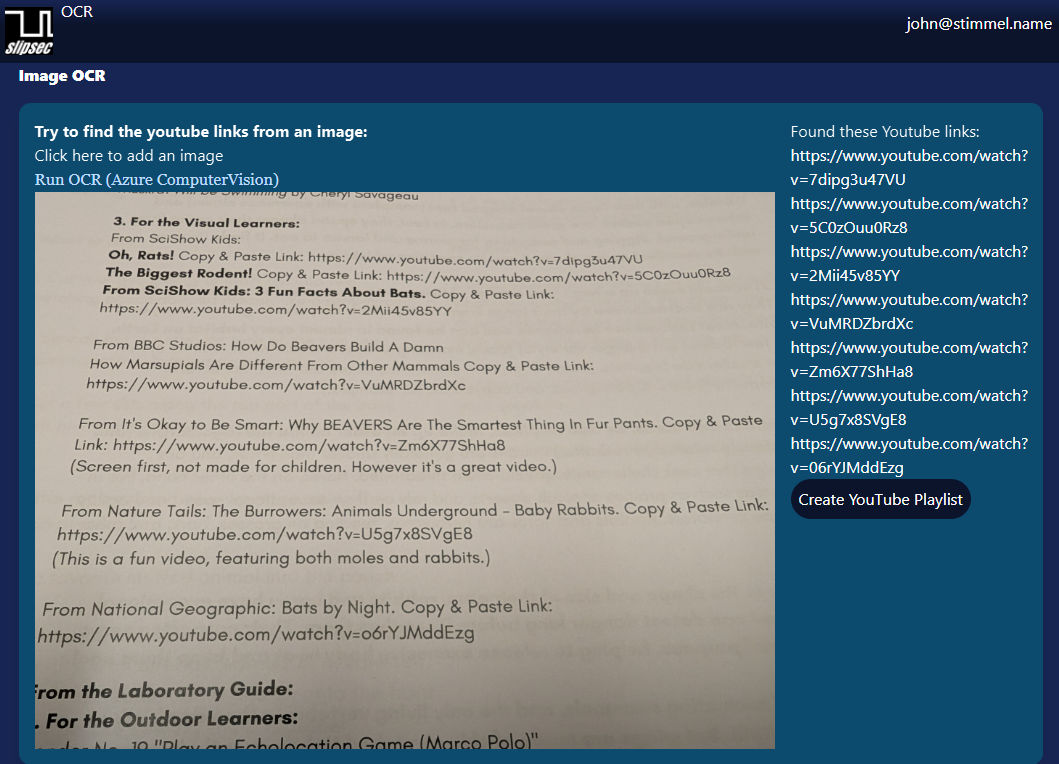
I "vibed" a chat-bridge app to sync across multiple platforms (think Discord, Telegram, Slack, Teams, etc). All in all it did pretty good. Enough Interface scaffolding for testability. Good enough DI to make testing feasible, and It made some tests.
The good stuff:
It was handy to boilerplate stuff, many tab-completion ideas were perfect, but far from all.
It was super effective when using it as a research assistant and not in agent mode.
Copilot was quite nice to be able to flip between different models including most of the time ones that didn't cost me anything. Those free models were quite good for trivial tasks like refactoring and research.
Anything where a close-to-default config or implementation was involved was great. This included setting up my nearly default CI/CD with GitHub actions. I didn't do anything weird or custom and used a very well documented pattern building a docker image and publishing that to my private ghcr so I can run it on my home lab.
Of those, my favorite usage was asking it for alternate design patterns or implementations for some ideas and then being able to jump from there to the actual documentation because… I don't trust AI summaries. I do like them for a summary where I don’t care if some of the details are possibly not 100% correct. Summarizing an news story, article or blog that I don't care about every detail being correct would count here.
There's some stuff I don't like or was outright terrible:
It got application logic just straight up wrong, attempting to store a channel-id not a message-id.
Smells
Inconsistency. There was some worse than other. Some things were implemented in different ways or using different patterns. Sometimes this made sense for example when Adapters for different platforms must target different API paradigms. Other times it was just a smell like when completely different patterns were used to integrate those adapters with the core of the app.
Duplicate implementations where a refactor to abstract a function or use an overload is just far better
Excessive safety. Really loved putting try-catch blocks EVERYWHERE. Especially bad for something like "no logger configured." when it is required or simply defaults to console and can never be null.
Hallucinations
APIs that simply don't exist
Trouble with current vs legacy things like trying to use deprecated API methods
Workflow issues
None of the models seemed to want to even attempt to use the PowerShell console properly. This was out of safety because it didn't want to risk any potential profile configurations it didn't know about but no models ever managed to properly escape quotes or special characters when using the console to debug. Most of them managed to work around the issue by writing .ps1 scripts and executing those.
When debugging issues the agents almost never cleaned up leftover scripts or comments or commented out sections once they resolved a bug. Even after prompting them to.
More trivial things
Naming. I guess this could be called a nit, but it came up with "EfBridgeMappingStore" for the repository… which is weird. I changed it to "BridgeRepository"
Adding non-current packages. I have no idea why it liked doing this but… it did.
I think I saved the most time and credit AI the most in… research. I didn't have to dig through volumes of extensive documentation or details to find the information I was looking for. I could ask for a link to the specific information I needed and I could have it dismiss the things that I knew did not apply or were irrelevant without having to go through them all myself.
Others have said this in less words, but it's the same theme as many have adopted. Use AI as a tool, not a solution. Treat it like a junior engineer and check the work it does. Like a junior it absolutely can offer some great ideas, but also it is often eager to provide solutions that add smell or at worse are simply broken or wrong.